
前言
需求背景:刚给 卡通网 增加了下面的百度的自动推送js代码去给百度提交链接,但由于代码是后加上的,因此,如果要把所有的文章都推送过去百度,就得把所有文章都点击一次;这操作如果使用计算机完成可以如何操作呢?
系统环境:Win 7,Python 2.7,Google Chrome 浏览器版本 74.0.3729.169(正式版本) (64 位)
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https') {
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else {
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();解决思路:使用 headless 浏览器 Selenium。编写 python 代码去操作 Selenium 点击打开所有需要推送的页面。
操作详细
一、环境准备
1、下载 ChromeDriver。Selenium 操作 chrome 浏览器需要有 ChromeDriver 驱动来协助。
通过淘宝镜像(https://npm.taobao.org/mirrors/chromedriver/)下载与 chrome 相应版本的ChromeDriver(即我的 chrome 版本是 74,那么 ChromeDriver 的版本也应该是 74,不然使用时会报错);然后把 ChromeDriver 放置于:C:\Program Files (x86)\Google\Chrome\Application\ (对应的 Chrome 安装目录下)
版本不一致会报类似下面错误
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.WebDriverException: Message: unknown error: Runtime.executionContextCreated has invalid 'context': {"auxData":{"frameId":"1902135EC45F5C7A8A0CD69740B466CA","isDefault":true,"type":"default"},"id":1,"name":"","origin":"://"}
(Session info: chrome=70.0.3538.102)
(Driver info: chromedriver=2.6.233026,platform=Windows NT 6.3 x86_64)2、因为没有安装 pip,需要安装 pip,用于安装 python 插件。如果你已经自带安装了 pip 请忽略此步骤。
(1) 下载安装 pip 的依赖包,setuptools(https://pypi.org/project/setuptools/#files)
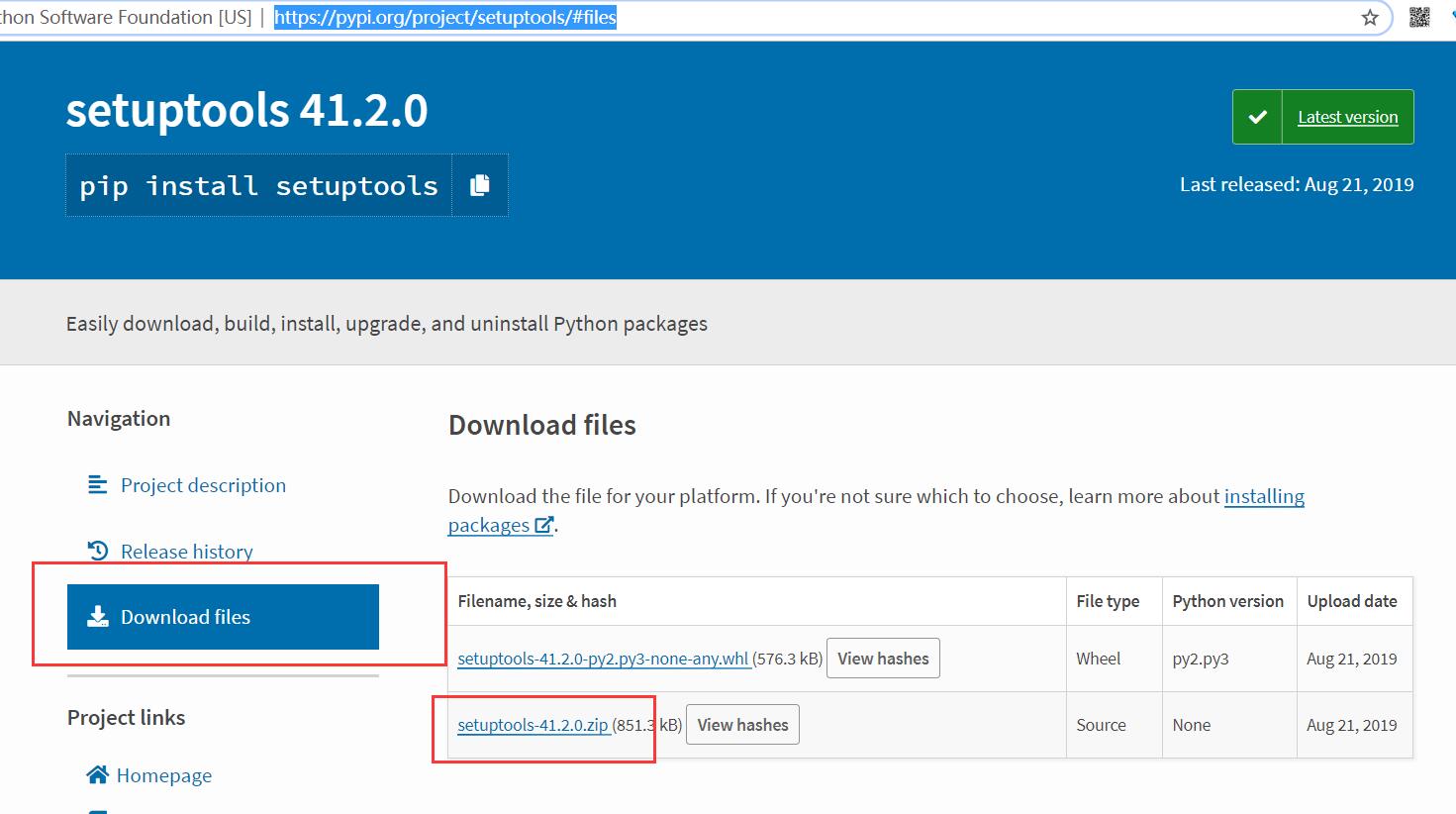
命令行下定位到下载解压的文件执行命令安装
python setup.py install如果不安装此工具直接走下一步会报下面错误:
D:\temp\sel> python setup.py install
Traceback (most recent call last):
File “setup.py”, line 6, in
from setuptools import setup, find_packages
ImportError: No module named setuptools
(2) 下载安装 pip(https://pypi.org/project/pip/#files)
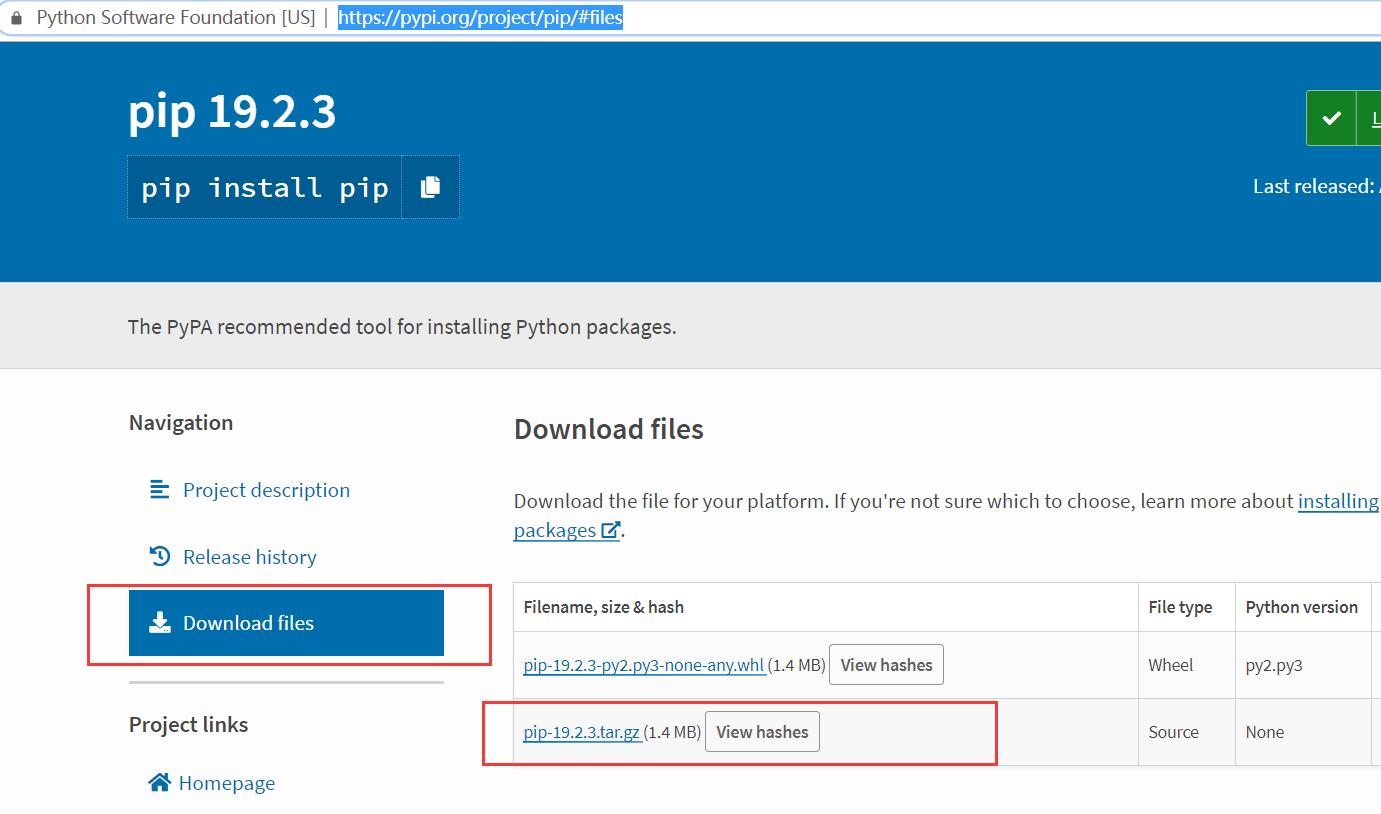
命令行下定位到下载解压的文件执行命令安装
python setup.py install3、命令行安装Selenium
用国内的镜像源来下载安装。
pip install selenium -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com如果用国外的源有可能安装失败,报下面错误:
Could not find a version that satisfies the requirement xxxx你的包名 (from versions: )
No matching distribution found for xxxx你的包名4、命令行安装等会会用到的schedule定时任务专用包
pip install schedule -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com二、编写 python 程序 (kt5.py) 处理
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
import schedule
chrome_options = Options()
chrome_options.add_argument("--headless")
# 打开kt5.cn网的最新一篇文章
base_url = "http://www.kt5.cn"
#对应的chromedriver的放置目录
driver = webdriver.Chrome(executable_path=(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'), chrome_options=chrome_options)
driver.get(base_url + "/2019/08/27/mahou-shoujo-2")
start_time=time.time()
print('this is start_time ',start_time)
count=0
def job():
global count
count += 1
driver.find_element_by_css_selector(".nav-previous>a").click()
driver.save_screenshot('screen_' + str(count) + '.png')
schedule.every(2).seconds.do(job)
while True:
schedule.run_pending()
time.sleep(1)
driver.close()
end_time=time.time()
print('this is end_time ',end_time)
主要思路就是先分析 卡通网 的结构,打开其最新一篇文章 《【魔法少女】唯美系列》,发现如果想把所有的文章都点一遍的话,可以使用的策略是由第一篇文章 《【魔法少女】唯美系列》 开始,使用 schedule 的定时任务每隔 2 秒去点击右下角的下一篇(css 选择器:.nav-previous>a,使用函数 driver.find_element_by_css_selector 来进行 dom 的获取),直到把所有的文章都点击打开一遍并录屏。
最后定位到 kt5.py 文件下,命令行执行:
python kt5.py可以在当前目录下面看到所有被访问页面的录屏图片